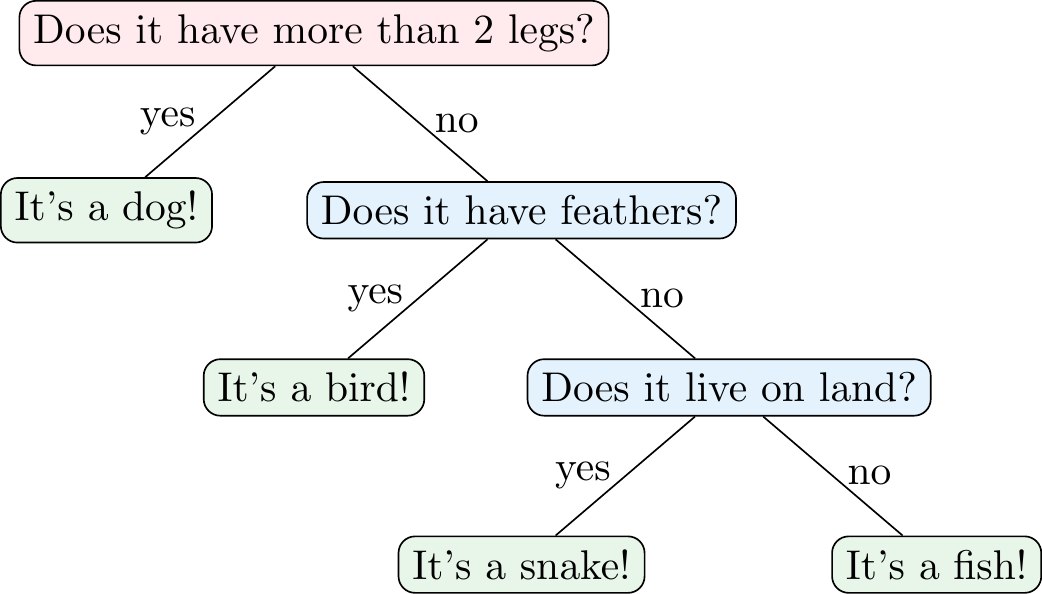
3 Decision Trees
Now that we have covered some of the basics of machine learning, we can start looking at some of the most popular machine learning algorithms. In this chapter, we will focus on Decision Trees and tree-based ensemble methods such as Random Forests and (Gradient) Boosted Trees.
3.1 What is a Decision Tree?
Decision trees, also called Classification and Regression Trees (CART) are a popular supervised learning method. As the name CART suggests, they are used for both classification and regression problems. They are simple to understand and interpret, and the process of building a decision tree is intuitive. Decision trees are also the foundation of more advanced ensemble methods like Random Forests and Boosting.
Figure 3.1 shows an example of a decision tree for a classification problem, i.e., a classification tree. In this case, the decision tree is used to classify animals into four categories: dogs, snakes, fish, and birds. The tree asks a series of questions about the features of the animal (e.g., number of legs, feathers, and habitat) and uses the answers to classify the animal. This means that the tree partitions the feature space into different regions that are associated with a particular class label.
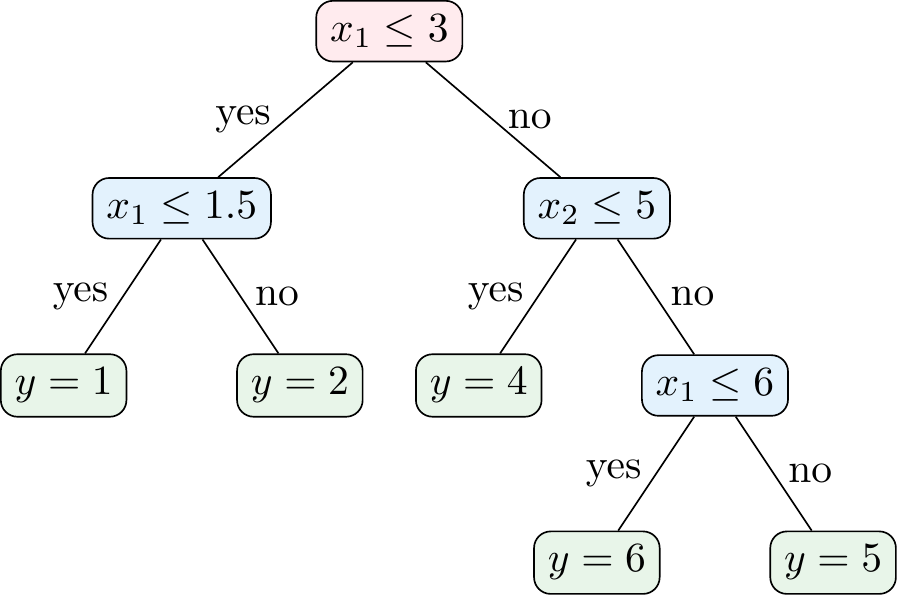
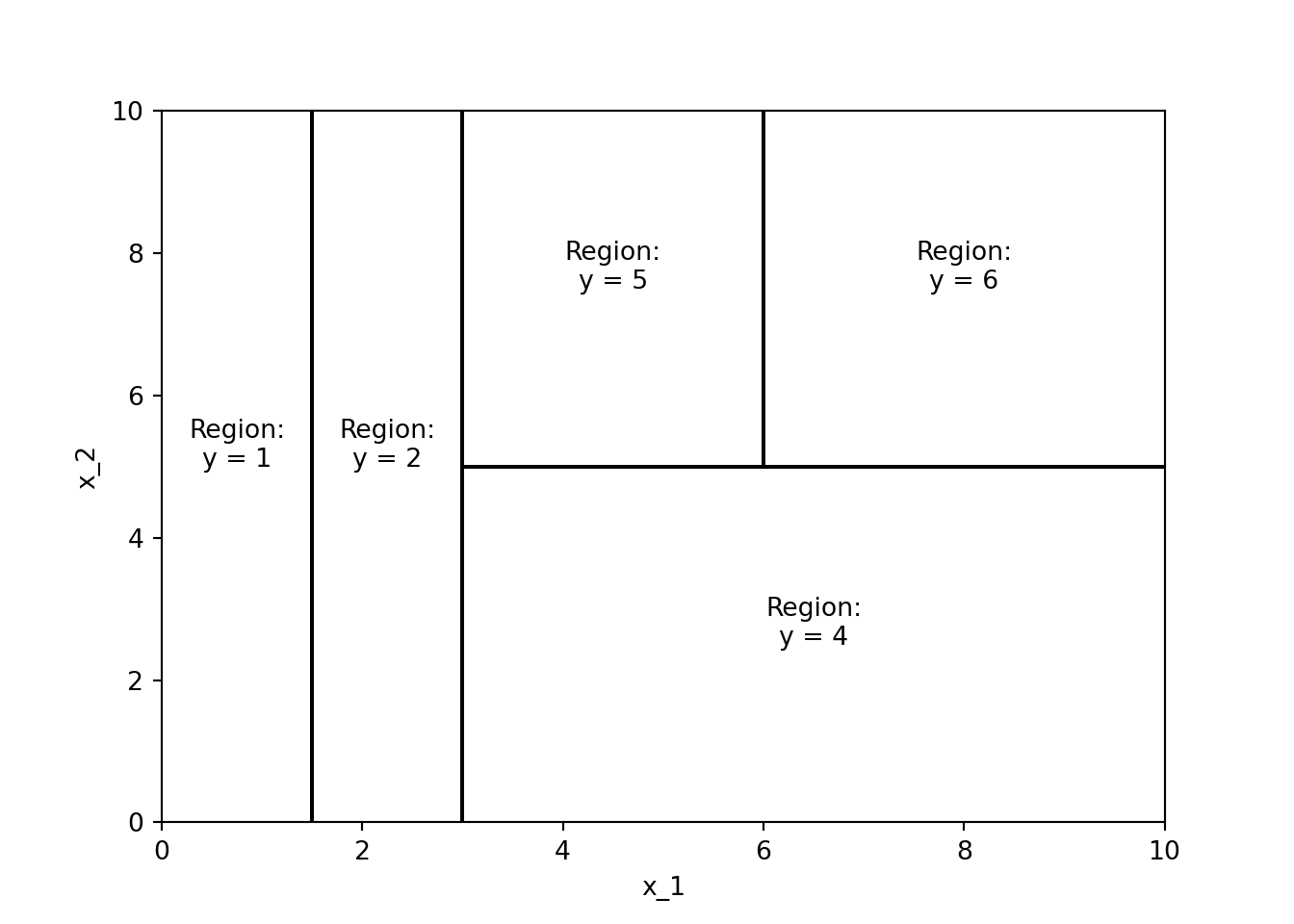
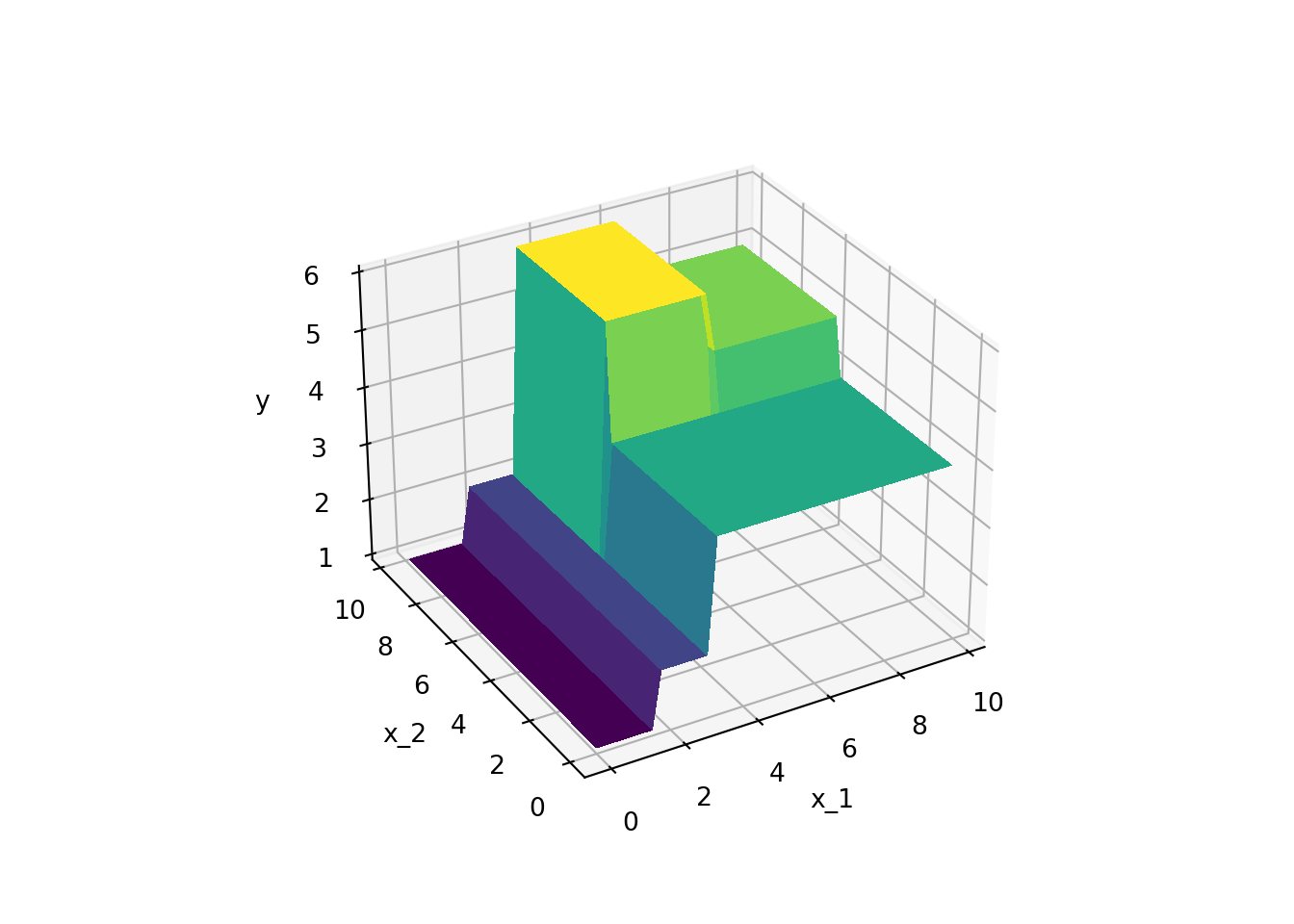
Figure 3.2 shows an example of a decision tree for a regression problem, i.e., a regression tree. In this case, the decision tree is used to predict some continuous variable \(y\) (e.g., a house price) based on features \(x_1\) and \(x_2\) (e.g., number of rooms and size of the property). As Figure 3.7 shows, the regression tree partitions the \((x_1,x_2)\)-space into different regions that are associated with a predicted value \(y\). Mathematically, the prediction of a regression tree can be expressed as
\[\hat{y} = \sum_{m=1}^{M} c_m \mathbb{1}(x \in R_m)\]
where \(R_m\) are the regions of the feature space, \(c_m\) are the predicted (i.e., average) values in the regions, \(\mathbb{1}(x \in R_m)\) is an indicator function that is 1 if \(x\) is in region \(R_m\) and 0 otherwise, and \(M\) is the number of regions.
Mini-Exercise
Given the decision tree in Figure 3.2, what would be the predicted value of \(y\) for the following data points?
- \((x_1, x_2) = (1, 1)\)
- \((x_1, x_2) = (2, 2)\)
- \((x_1, x_2) = (2, 8)\)
- \((x_1, x_2) = (10, 4)\)
- \((x_1, x_2) = (7, 8)\)
3.2 Terminology
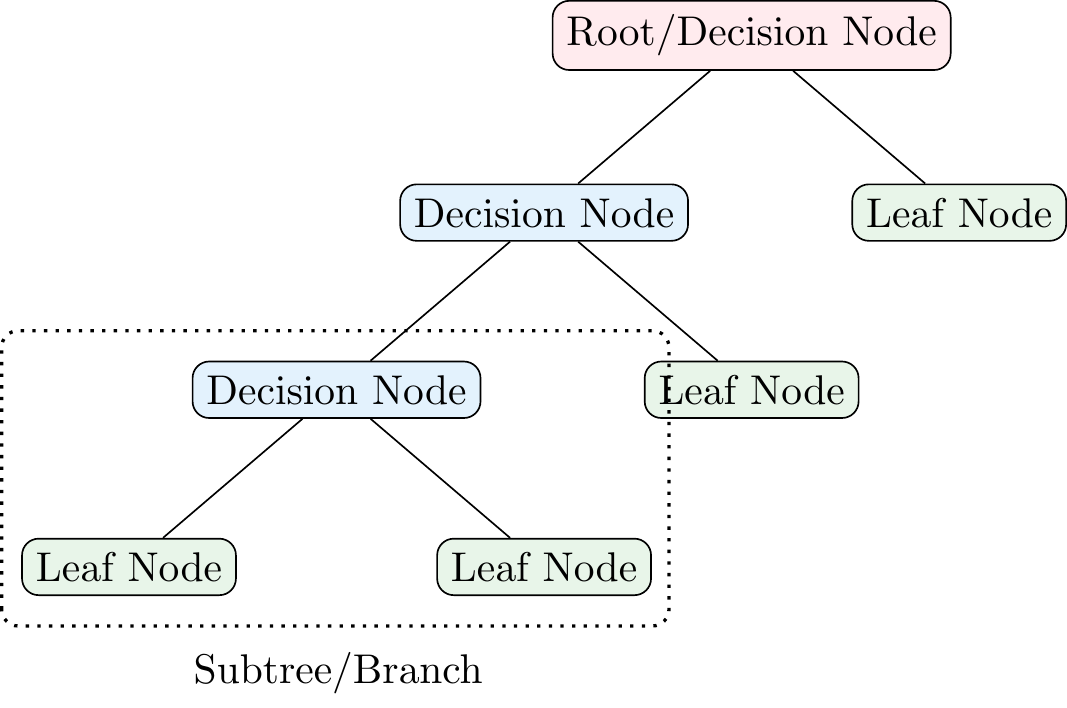
Figure 3.4 shows some of the terminology that you might encounter in decision trees. The root node is the first node in the tree. The root node is split into decision nodes (or leaf nodes) based on the values of the features. The decision nodes are further split into decision nodes or leaf nodes. The leaf nodes represent the final prediction of the model. A subtree or branch is a part of the tree that starts at a decision node and ends at a leaf node. The depth of a tree is the length of the longest path from the root node to a leaf node.
Furthermore, one can also differentiate between child and parent nodes. A child node is a node that results from a split (e.g., the first (reading from the top) decision node and leaf node in Figure 3.4 are child nodes of the root node). The parent node is the node that is split to create the child nodes (e.g., the root node in Figure 3.4 is the parent node of the first decision node and leaf node).
3.3 How To Grow a Tree
A key question is how to determine the order of variables and thresholds that are used in all the splits of a decision tree. There are different algorithms to grow a decision tree, but the most common one is the CART algorithm. The CART algorithm is a greedy algorithm that grows the tree in a top-down manner. The reason for this algorithm choice is that it is computationally infeasible to consider all possible (fully grown) trees to find the best-performing one. So, the CART algorithm grows the tree in a step-by-step manner choosing the splits in a greedy manner (i.e., choosing the one that performs best at that step). This means that the algorithm does not consider the future consequences of the current split and may not find the optimal tree.
The basic idea is to find a split that minimizes some loss function \(Q^s\) and to repeat this recursively for all resulting child nodes. Suppose we start from zero, meaning that we first need to determine the root node. We compute the loss function \(Q^s\) for all possible splits \(s\) that we can make. This means we need to consider all variables in our dataset (and all split thresholds) and choose the one that minimizes the loss \(Q^s\). We then repeat this process for each of the child nodes, and so on, until we reach a stopping criterion. Figure 3.5 shows an example of a candidate split.
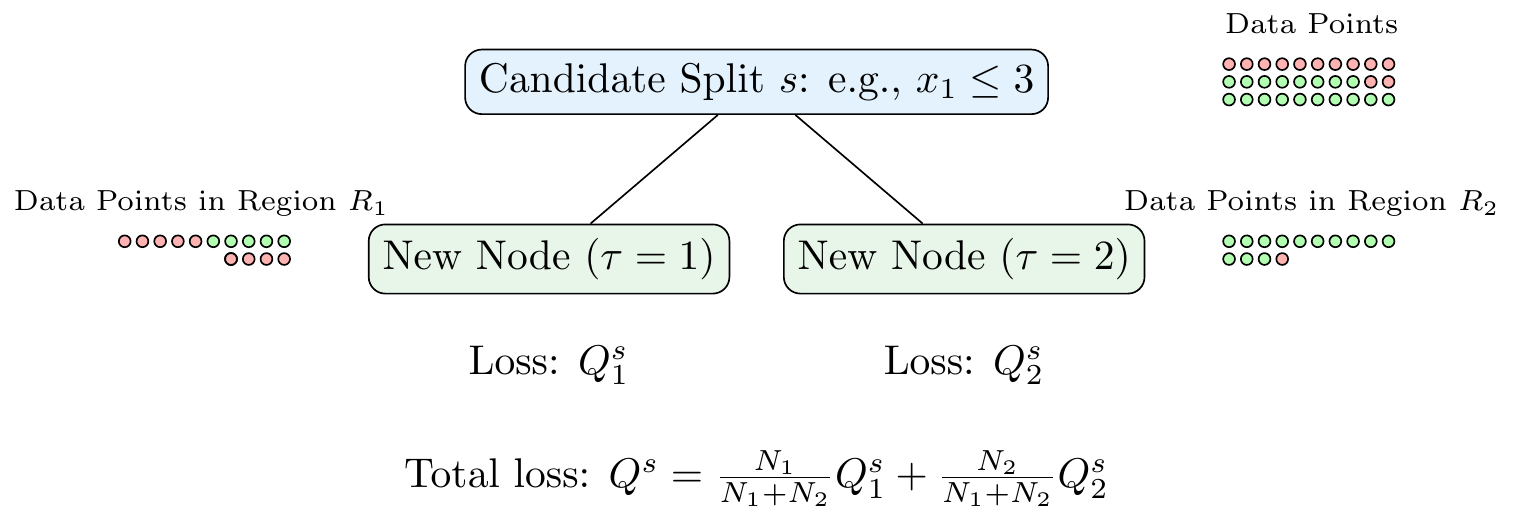
Let \(\tau\) denote the index of a leaf node with each leaf node \(\tau\) corresponding to a region \(R_{\tau}\) with \(N_{\tau}\) data points. In the case of a classification problem, the loss function is typically either the Gini impurity
\[Q^s_{\tau} = \sum_{k=1}^{K} p_{\tau k} (1 - p_{\tau k}) = 1- \sum_{k=1}^K p_{\tau k}^2\]
or the cross-entropy
\[Q^s_{\tau} = -\sum_{k=1}^{K} p_{\tau k} \log(p_{\tau k})\]
where \(p_{\tau k}\) is the proportion of observations in region \(R_{\tau}\) that belong to class \(k\) and \(K\) is the number of classes. Note that both measures become zero when all observations in the region belong to the same class (i.e., \(p_{\tau k} = 1\) or \(p_{\tau k} = 0\)). This is the ideal case for a classification problem: we say that the node is pure.
In the case of a regression problem, the loss function is typically the mean squared error (MSE)
\[Q^s_{\tau} = \frac{1}{N_{\tau}} \sum_{i \in R_{\tau}} (y_i - \hat{y}_{\tau})^2\]
where \(\hat{y}_{\tau}\) is the predicted value of the target variable \(y\) in region \(R_{\tau}\)
\[\hat{y}_{\tau} = \frac{1}{N_{\tau}} \sum_{i \in R_{\tau}} y_i,\]
i.e., the average of the target variable in region \(R_{\tau}\).
The total loss of a split \(Q^s\) is then the weighted sum of the loss functions of the child nodes
\[Q^s = \frac{N_1}{N_1+N_2}Q^s_{1} + \frac{N_2}{N_1+N_2}Q^s_{2}\]
where \(N_1\) and \(N_2\) are the number of data points in the child nodes.
Once we have done this for the root node, we repeat the process for each child node. Then, we repeat it for the child nodes of the child nodes, and so on, until we reach a stopping criterion. The stopping criterion can be, for example, a maximum depth of the tree, a minimum number of data points in a leaf node, or a minimum reduction in the loss function.
3.3.1 Example: Classification Problem
Suppose you have the data in Table 3.1. The goal is to predict whether a bank will default based on two features: whether the bank is systemically important and its Common Equity Tier 1 (CET1) ratio (i.e., the ratio of CET1 capital to risk-weighted assets). The CET1 ratio is a measure of a bank’s financial strength.
| Default | Systemically Important Bank | CET1 Ratio (in %) |
|---|---|---|
| Yes | No | 8.6 |
| No | No | 9 |
| Yes | Yes | 10.6 |
| Yes | Yes | 10.8 |
| No | No | 11.2 |
| No | No | 11.5 |
| No | Yes | 12.4 |
Given that you only have two features, CET1 Ratio and whether it is a systemically important bank, you only have two possible variables for the root node. However, since CET1 is a continuous variable, there are potentially many thresholds that you could use to split the data. To find this threshold, we need to calculate the Gini impurity of each possible split and choose the one that minimizes the impurity.
| CET1 Ratio Threshold | Q₁ | Q₂ | Q |
|---|---|---|---|
| 8.8 | 0 | 0.44 | 0.38 |
| 9.8 | 0.5 | 0.48 | 0.49 |
| 10.7 | 0.44 | 0.38 | 0.4 |
| 11 | 0.38 | 0 | 0.21 |
| 11.35 | 0.48 | 0 | 0.34 |
| 11.95 | 0.5 | 0 | 0.43 |
According to Table 3.2, the best split is at a CET1 ratio of 7.0%. The Gini impurity for \(\text{CET1}\leq 11\%\) is 0.38, the Gini impurity of \(\text{CET1}>11\%\) is 0, and the total impurity is 0.21. However, we could also split based on whether a bank would be systemically important. In this case, the Gini impurity of the split is 0.40. This means that the best split is based on the CET1 ratio. We split the data into two regions: one with a CET1 ratio of 11.0% or less and one with a CET1 ratio of more than 11.0%.
Note that the child node for a CET1 ratio of more than \(11.0\%\) is already pure, i.e., all banks in this region are not defaulting. However, the child node for a CET1 ratio of \(11.0\%\) or less is not pure meaning that we can do additional splits as shown in Figure 3.6. In particular, both, the split at a CET1 ratio of 8.8% and the split based on whether a bank is systemically important yield a Gini impurity of 0.25. We choose the split based on whether a bank is systemically important as the next split, which means we can do the final split based on the CET1 ratio.
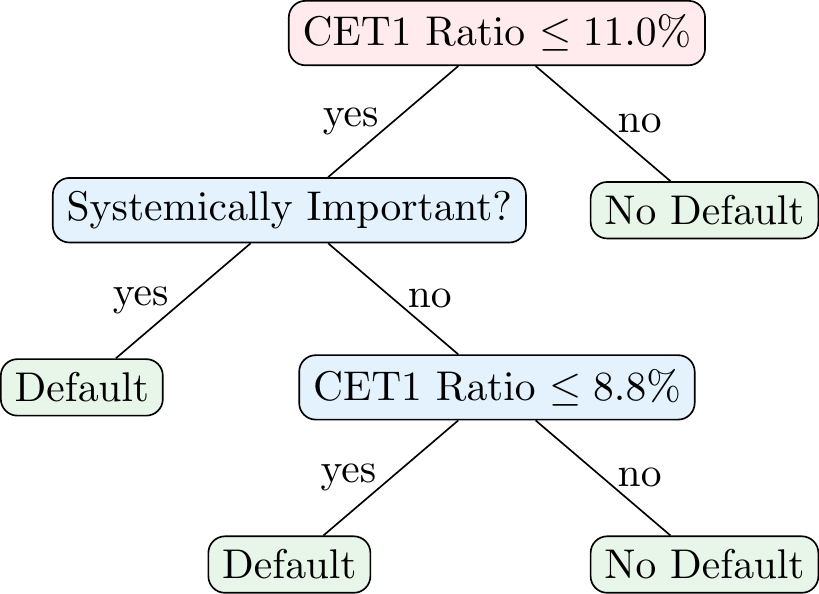
3.3.2 Stopping Criteria and Pruning a Tree
A potential problem with decision trees is that they can overfit the training data. In principle, we can get the error down to zero if we just make enough splits. This means that the tree can become too complex and capture noise in the data rather than the underlying relationship. To prevent this, we usually set some early stopping criteria like
- A maximum depth of the tree,
- A minimum number of data points in a leaf node,
- A minimum number of data points required in a decision node for a split,
- A minimum reduction in the loss function, or
- A maximum number of leaf nodes,
which will prevent the tree from growing too large and all the nodes from becoming pure. We can also use a combination of these criteria. In the Python applications, we will see how to set some of these stopping criteria.
Figure 3.7 shows an example of how stopping criteria affect the fit of a decision tree. Note that without any stopping criteria, the tree fits the data perfectly but is likely to overfit. By setting a maximum depth or a minimum number of data points in a leaf node, we can prevent the tree from overfitting the data.
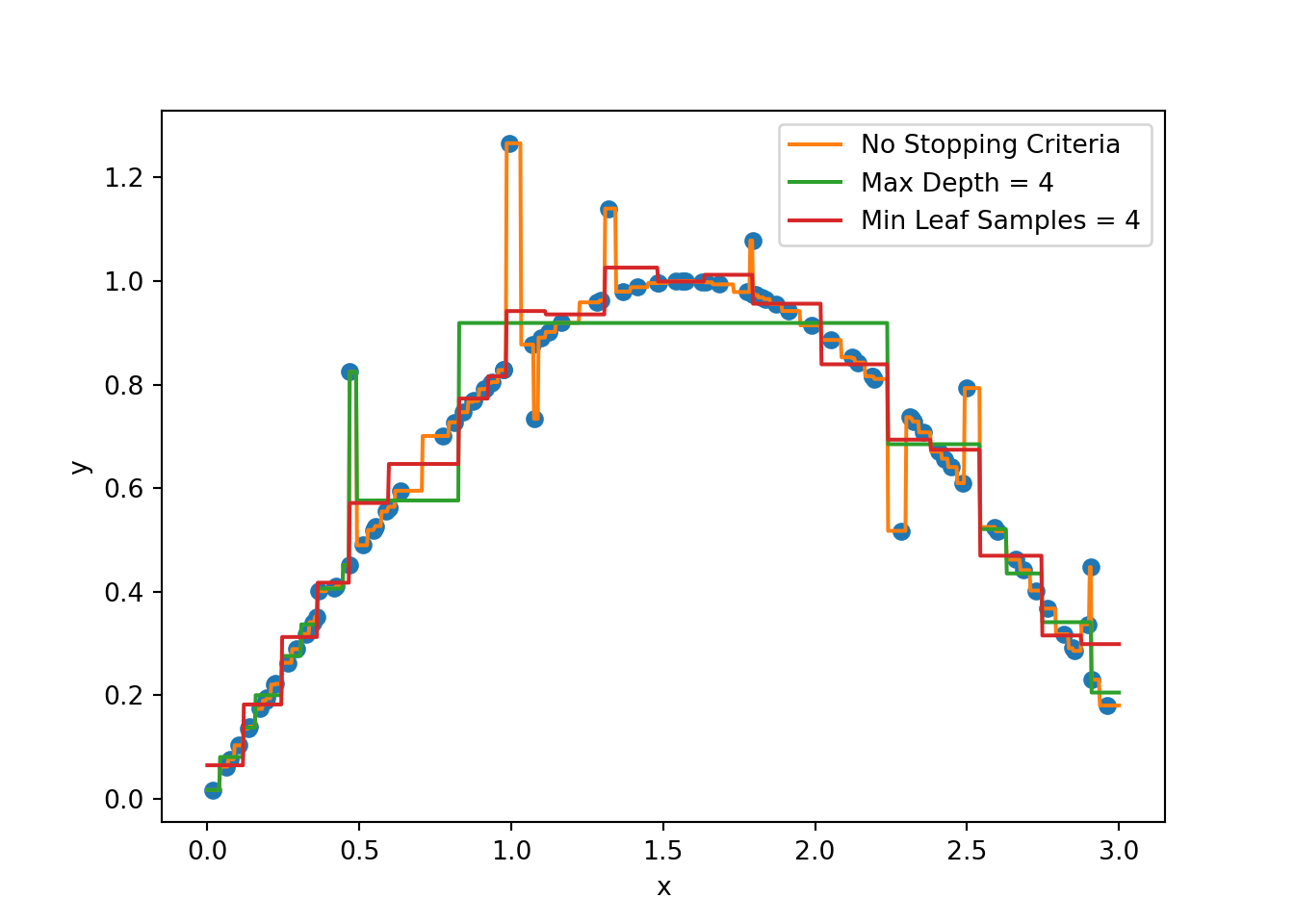
Another way to prevent overfitting is to prune the tree, i.e., to remove nodes from the tree according to certain rules. This is done after (not during) growing the tree. One common approach is to use cost-complexity pruning. The idea is related to regularization that we have seen before, i.e., we add a term to the loss functions above that penalizes tree complexity. The pruning process is controlled by a hyperparameter \(\lambda\) that determines the trade-off between the complexity of the tree and its fit to the training data.
Mini-Exercise
How would the decision tree in Figure 3.6 look like if
- we required a minimum of 2 data points in a leaf node?
- we required a maximum depth of 2?
- we required a maximum depth of 2 and a minimum of 3 data points in a leaf node?
- we required a minimum of 3 data points for a split?
- we required a minimum of 5 data points for a split?
3.4 Advantages and Disadvantages
As noted by Murphy (2022), decision trees are popular because of some of the advantages they offer
- Easy to interpret
- Can handle mixed discrete and continuous inputs
- Insensitive to monotone transformations of the inputs
- Automatic variable selection
- Relatively robust to outliers
- Fast to fit and scale well to large data sets
- Can handle missing input features1
Their disadvantages include
- Not very accurate at prediction compared to other kinds of models (note, for example, the piece-wise constant nature of the predictions in regression problems)
- They are unstable: small changes to the input data can have large effects on the structure of the tree (small changes at the top can affect the rest of the tree)
3.5 Ensemble Methods
Decision trees are powerful models, but they can be unstable. To address these issues, we can use ensemble methods that combine multiple decision trees to improve the performance of the model. The two most popular ensemble methods are Random Forests and Boosting.
3.5.1 Random Forests
The idea of Random Forests is to build a large number of trees (also called weak learners in this context), each of which is trained on a random subset of the data. The predictions of the trees are then averaged in regression tasks or determined through majority voting in the case of classification tasks to make the final prediction. Training multiple trees on random subsets of the data is also called bagging (short for bootstrap aggregating). Random Forests adds an additional layer of randomness by selecting a random subset of features for each tree. This means that each tree is trained on a different subset of the data and a different subset of features.
The basic steps of the Random Forest algorithm are as follows:
- Bootstrapping: Randomly draw \(N\) samples with replacement from the training data.
- Grow a tree: For each node of the tree, randomly select \(m\) features from the \(p\) features in the bootstrap dataset and find the best split based on these \(m\) features.
- Repeat: Repeat steps 1 and 2 \(B\) times to grow \(B\) trees.
- Prediction: To get the prediction for a new data point, average the predictions of all trees in the case of regression or use a majority vote in the case of classification.
Note that because we draw samples with replacement, some samples will not be included in the bootstrap sample. These samples are called out-of-bag (OOB) samples. The OOB samples can be used to estimate the performance of the model without the need for cross-validation since it is “performed along the way” (Hastie, Tibshirani, and Friedman (2009)). The OOB error is almost identical to the error obtained through N-fold cross-validation.
3.5.2 Boosting
Another popular ensemble method is Boosting. The idea behind boosting is to train a sequence of weak learners (e.g., decision trees), each of which tries to correct the mistakes of the previous one. The predictions of the weak learners are then combined to make the final prediction. Note how this differs from Random Forests where the trees are trained independently of each other in parallel, while here we sequentially train the trees to fix the mistakes of the previous ones. The basic steps can be roughly summarized as follows:
- Initialize the model: Construct a base tree with just a root node. In the case of a regression problem, the prediction could be the mean of the target variable. In the case of a classification problem, the prediction could be the log odds of the target variable.
- Train a weak learner: Train a weak learner on the data. The weak learner tries to correct the mistakes of the previous model.
- Update the model: Update the model by adding the weak learner to the model. The added weak learner is weighted by a learning rate \(\eta\).
- Repeat: Repeat steps 2 and 3 until we have grown \(B\) trees.
XGBoost (eXtreme Gradient Boosting) is a popular implementation of the (gradient) boosting algorithm. It is known for its performance and is widely used in machine learning competitions. The algorithm is based on the idea of gradient boosting, which is a generalization of boosting. We will see how to implement XGBoost in Python but will not go into the details of the algorithm here. Other popular implementations of the boosting algorithm are AdaBoost and LightGBM.
3.5.3 Interpreting Ensemble Methods
A downside of using ensemble methods is that you lose the interpretability of a single decision tree. However, there are ways to interpret ensemble methods. One way is to look at the feature importance. Feature importance tells you how much each feature contributes to the reduction in the loss function. The idea is that features that are used in splits that lead to a large reduction in the loss function are more important. Murphy (2022) shows that the feature importance of feature \(k\) is
\[R_k(b)=\sum_{j=1}^{J-1} G_j \mathbb{I}(v_j=k)\]
where the sum is over all non-leaf (internal) nodes, \(G_j\) is the loss reduction (gain) at node \(j\), and \(v_j = k\) if node \(j\) uses feature \(k\). Simply put, we sum up all gains of the splits that use feature \(k\). Then, we average over all trees in our ensemble to get the feature importance of feature \(k\)
\[R_k = \frac{1}{B}\sum_{b=1}^{B} R_k(b).\]
Note that the resulting \(R_k\) are sometimes normalized such that the maximum value is 100. This means that the most important feature has a feature importance of 100 and all other features are scaled accordingly. Note that feature importance can in principle also be computed for a single decision tree.
Warning
Note that feature importance tends to favor continuous variables and variables with many categories (for an example see here). As an alternative, one can use permutation importance which is a model-agnostic way to compute the importance of different features. The idea is to shuffle the values of a feature in the test data set and see how much the model performance decreases. The more the performance decreases, the more important the feature is.
3.6 Python Implementation
Let’s have a look at how to implement a decision tree in Python. Again, we need to first import the required packages and load the data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score, recall_score, precision_score, roc_curve
from sklearn.inspection import permutation_importance
pd.set_option('display.max_columns', 50) # Display up to 50 columns
from io import BytesIO
from urllib.request import urlopen
from zipfile import ZipFile
import os.path
# Check if the file exists
if not os.path.isfile('data/card_transdata.csv'):
print('Downloading dataset...')
# Define the dataset to be downloaded
zipurl = 'https://www.kaggle.com/api/v1/datasets/download/dhanushnarayananr/credit-card-fraud'
# Download and unzip the dataset in the data folder
with urlopen(zipurl) as zipresp:
with ZipFile(BytesIO(zipresp.read())) as zfile:
zfile.extractall('data')
print('DONE!')
else:
print('Dataset already downloaded!')
# Load the data
df = pd.read_csv('data/card_transdata.csv')Dataset already downloaded!This is the dataset of credit card transactions from Kaggle.com which we have used before. Recall that the target variable \(y\) is fraud, which indicates whether the transaction is fraudulent or not. The other variables are the features \(x\) of the transactions.
df.head(20)| distance_from_home | distance_from_last_transaction | ratio_to_median_purchase_price | repeat_retailer | used_chip | used_pin_number | online_order | fraud | |
|---|---|---|---|---|---|---|---|---|
| 0 | 57.877857 | 0.311140 | 1.945940 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 10.829943 | 0.175592 | 1.294219 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 5.091079 | 0.805153 | 0.427715 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | 2.247564 | 5.600044 | 0.362663 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 4 | 44.190936 | 0.566486 | 2.222767 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 5 | 5.586408 | 13.261073 | 0.064768 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 6 | 3.724019 | 0.956838 | 0.278465 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 7 | 4.848247 | 0.320735 | 1.273050 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 8 | 0.876632 | 2.503609 | 1.516999 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 9 | 8.839047 | 2.970512 | 2.361683 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 10 | 14.263530 | 0.158758 | 1.136102 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 11 | 13.592368 | 0.240540 | 1.370330 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| 12 | 765.282559 | 0.371562 | 0.551245 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 13 | 2.131956 | 56.372401 | 6.358667 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| 14 | 13.955972 | 0.271522 | 2.798901 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 15 | 179.665148 | 0.120920 | 0.535640 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 |
| 16 | 114.519789 | 0.707003 | 0.516990 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 17 | 3.589649 | 6.247458 | 1.846451 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 18 | 11.085152 | 34.661351 | 2.530758 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 19 | 6.194671 | 1.142014 | 0.307217 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
df.describe()| distance_from_home | distance_from_last_transaction | ratio_to_median_purchase_price | repeat_retailer | used_chip | used_pin_number | online_order | fraud | |
|---|---|---|---|---|---|---|---|---|
| count | 1000000.000000 | 1000000.000000 | 1000000.000000 | 1000000.000000 | 1000000.000000 | 1000000.000000 | 1000000.000000 | 1000000.000000 |
| mean | 26.628792 | 5.036519 | 1.824182 | 0.881536 | 0.350399 | 0.100608 | 0.650552 | 0.087403 |
| std | 65.390784 | 25.843093 | 2.799589 | 0.323157 | 0.477095 | 0.300809 | 0.476796 | 0.282425 |
| min | 0.004874 | 0.000118 | 0.004399 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 3.878008 | 0.296671 | 0.475673 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 9.967760 | 0.998650 | 0.997717 | 1.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 |
| 75% | 25.743985 | 3.355748 | 2.096370 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 |
| max | 10632.723672 | 11851.104565 | 267.802942 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 distance_from_home 1000000 non-null float64
1 distance_from_last_transaction 1000000 non-null float64
2 ratio_to_median_purchase_price 1000000 non-null float64
3 repeat_retailer 1000000 non-null float64
4 used_chip 1000000 non-null float64
5 used_pin_number 1000000 non-null float64
6 online_order 1000000 non-null float64
7 fraud 1000000 non-null float64
dtypes: float64(8)
memory usage: 61.0 MB3.6.1 Data Preprocessing
Since we have already explored the dataset in the previous notebook, we can skip that part and move directly to the data preprocessing.
We will again split the data into training and test sets using the train_test_split function
X = df.drop('fraud', axis=1) # All variables except `fraud`
y = df['fraud'] # Only our fraud variables
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size = 0.3, random_state = 42)Then we can do the feature scaling to ensure our non-binary variables have mean zero and variance 1
def scale_features(scaler, df, col_names, only_transform=False):
# Extract the features we want to scale
features = df[col_names]
# Fit the scaler to the features and transform them
if only_transform:
features = scaler.transform(features.values)
else:
features = scaler.fit_transform(features.values)
# Replace the original features with the scaled features
df[col_names] = features
col_names = ['distance_from_home', 'distance_from_last_transaction', 'ratio_to_median_purchase_price']
scaler = StandardScaler()
scale_features(scaler, X_train, col_names)
scale_features(scaler, X_test, col_names, only_transform=True)3.6.2 Implementing a Decision Tree Classifier
We can now implement a decision tree model using the DecisionTreeClassifier class from the sklearn.tree module. Fitting the model to the data is almost the same as when we used logistic regression
clf_dt = DecisionTreeClassifier(random_state=0).fit(X_train, y_train)We can visualize the tree using the plot_tree function from the sklearn.tree module
plot_tree(clf_dt, filled=True, feature_names = X_train.columns.to_list())
plt.show()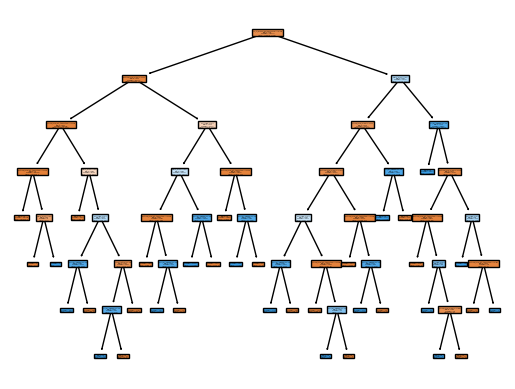
The tree is quite large and it’s difficult to see details. Let’s only look at the first level of the tree
plot_tree(clf_dt, max_depth=1, filled=True, feature_names = X_train.columns.to_list(), fontsize=10)
plt.show()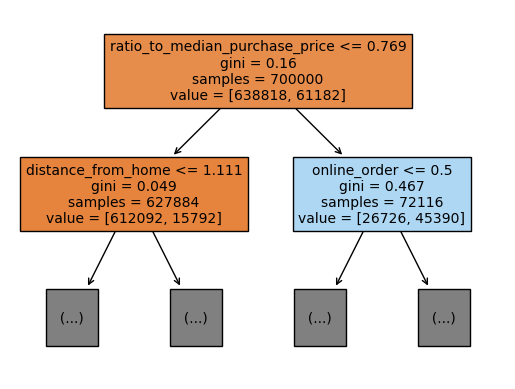
Recall from the data exploration that ratio_to_median_purchase_price was highly correlated with fraud. The decision tree model seems to have picked up on this as well since the first split is based on this variable. Also, note that the order in which the variables are split can differ between different branches of the tree.
We can also make predictions using the model and evaluate its performance using the same functions as before
y_pred_dt = clf_dt.predict(X_test)
y_proba_dt = clf_dt.predict_proba(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_dt)}")
print(f"Precision: {precision_score(y_test, y_pred_dt)}")
print(f"Recall: {recall_score(y_test, y_pred_dt)}")
print(f"ROC AUC: {roc_auc_score(y_test, y_proba_dt[:, 1])}")Accuracy: 0.9999833333333333
Precision: 0.9999237223493517
Recall: 0.999885587887571
ROC AUC: 0.999939141362689The decision tree performs substantially better than the logistic regression. The ROC AUC score is much closer to the maximum value of 1 and we have an almost perfect classifier
# Compute the ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_proba_dt[:, 1])
# Plot the ROC curve
plt.plot(fpr, tpr)
plt.plot([0, 1], [0, 1], linestyle='--', color='grey')
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.title('ROC Curve')
plt.show()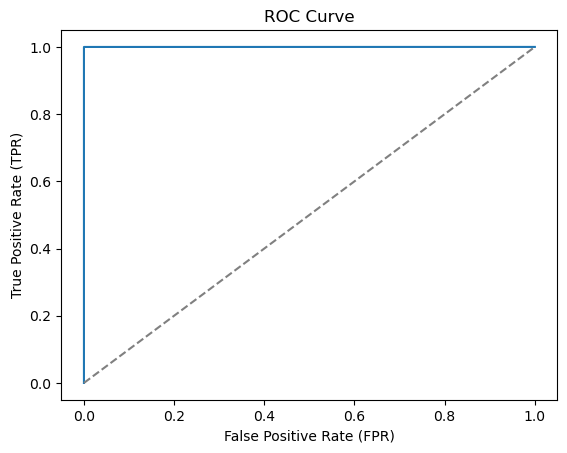
Let’s also check the confusion matrix to see where we still make mistakes
conf_mat = confusion_matrix(y_test, y_pred_dt, labels=[1, 0]).transpose() # Transpose the sklearn confusion matrix to match the convention in the lecture
sns.heatmap(conf_mat, annot=True, cmap='Blues', fmt='g', xticklabels=['Fraud', 'No Fraud'], yticklabels=['Fraud', 'No Fraud'])
plt.xlabel("Actual")
plt.ylabel("Predicted")
plt.show()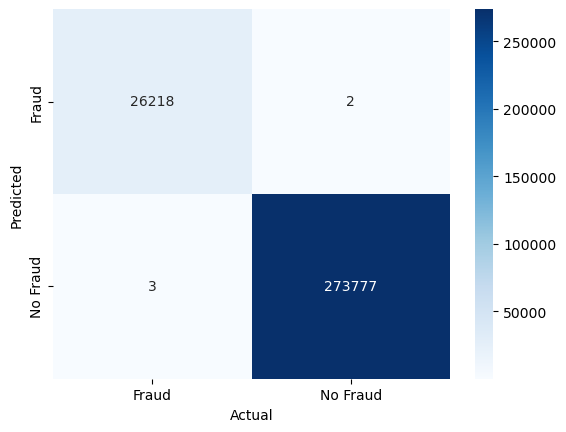
There are only 3 false negatives, i.e., fraudulent transactions that we did not detect. There are also 2 false positives, i.e., “false alarms”, where non-fraudulent transactions were classified as fraudulent. The decision tree classifier is almost perfect which is a bit suspicious. We might have been lucky in the sense that the training and test sets were split in a way that the model performs very well. We should not expect this to be the case in general. It might be better to use cross-validation to get a more reliable estimate of the model’s performance.
3.6.3 Implementing a Random Forest Classifier
We can also implement a random forest model using the RandomForestClassifier class from the sklearn.ensemble module. Fitting the model to the data is almost the same as when we used logistic regression and decision trees
clf_rf = RandomForestClassifier(random_state = 0).fit(X_train, y_train)Note that it takes a bit longer to train the Random Forest since we have to train many trees (the default setting is 100). We can also make predictions using the model and evaluate its performance using the same functions as before
y_pred_rf = clf_rf.predict(X_test)
y_proba_rf = clf_rf.predict_proba(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_rf)}")
print(f"Precision: {precision_score(y_test, y_pred_rf)}")
print(f"Recall: {recall_score(y_test, y_pred_rf)}")
print(f"ROC AUC: {roc_auc_score(y_test, y_proba_rf[:, 1])}")Accuracy: 0.9999833333333333
Precision: 1.0
Recall: 0.9998093131459517
ROC AUC: 0.9999999993035008As expected, the Random Forest performs better than the Decision Tree in the metrics we have used. Now, let’s also check the confusion matrix to see where we still make mistakes
conf_mat = confusion_matrix(y_test, y_pred_rf, labels=[1, 0]).transpose() # Transpose the sklearn confusion matrix to match the convention in the lecture
sns.heatmap(conf_mat, annot=True, cmap='Blues', fmt='g', xticklabels=['Fraud', 'No Fraud'], yticklabels=['Fraud', 'No Fraud'])
plt.xlabel("Actual")
plt.ylabel("Predicted")
plt.show()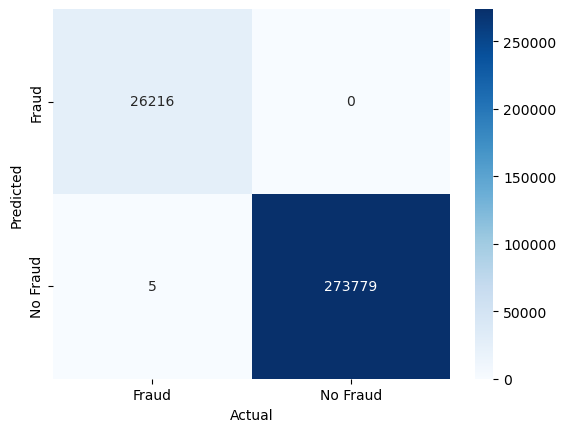
There are still some false negatives, but the number of false positives has decreased compared to the Decision Tree model.
3.6.4 Implementing a XGBoost Classifier
Let’s also have a look at the XGBoost classifier. We can implement the model using the XGBClassifier class from the xgboost package. Fitting the model to the data is almost the same as when we used logistic regression, decision trees, and random forests, even though it is not part of the sklearn package. This is because the xgboost package is designed to work well with the sklearn package. Let’s fit the model to the data
clf_xgb = XGBClassifier(random_state = 0).fit(X_train, y_train)y_pred_xgb = clf_xgb.predict(X_test)
y_proba_xgb = clf_xgb.predict_proba(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred_xgb)}")
print(f"Precision: {precision_score(y_test, y_pred_xgb)}")
print(f"Recall: {recall_score(y_test, y_pred_xgb)}")
print(f"ROC AUC: {roc_auc_score(y_test, y_proba_xgb[:, 1])}")Accuracy: 0.9983366666666667
Precision: 0.9893835616438356
Recall: 0.9916097784218756
ROC AUC: 0.999973496046352Let’s also check the confusion matrix to see where we still make mistakes
conf_mat = confusion_matrix(y_test, y_pred_xgb, labels=[1, 0]).transpose() # Transpose the sklearn confusion matrix to match the convention in the lecture
sns.heatmap(conf_mat, annot=True, cmap='Blues', fmt='g', xticklabels=['Fraud', 'No Fraud'], yticklabels=['Fraud', 'No Fraud'])
plt.xlabel("Actual")
plt.ylabel("Predicted")
plt.show()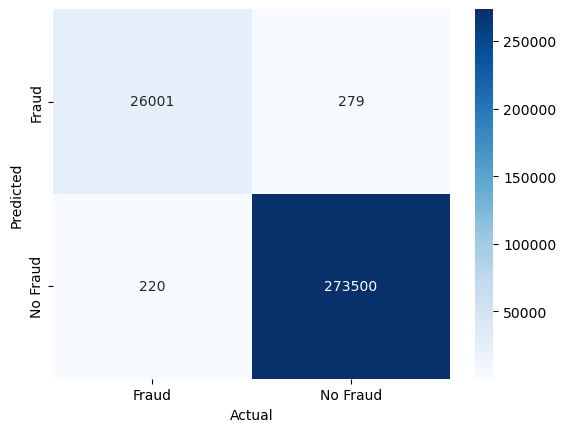
The XGBoost model seems to perform a bit worse than the Random Forest model. There are more false negatives and false positives. However, the model is still very good at detecting fraudulent transactions and has a high ROC AUC score. Adjusting the hyperparameters of the model might improve its performance.
3.6.5 Feature Importance
We can also look at the feature importance of each model. The feature importance is a measure of how much each feature contributes to the model’s predictions. Let’s start with the Decision Tree model
# Create a DataFrame with the feature importance
df_feature_importance_dt = pd.DataFrame({'Feature': X_train.columns, 'Importance': clf_dt.feature_importances_})
df_feature_importance_dt = df_feature_importance_dt.sort_values('Importance', ascending=False)
# Plot the feature importance
plt.barh(df_feature_importance_dt['Feature'], df_feature_importance_dt['Importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance - Decision Tree')
plt.show()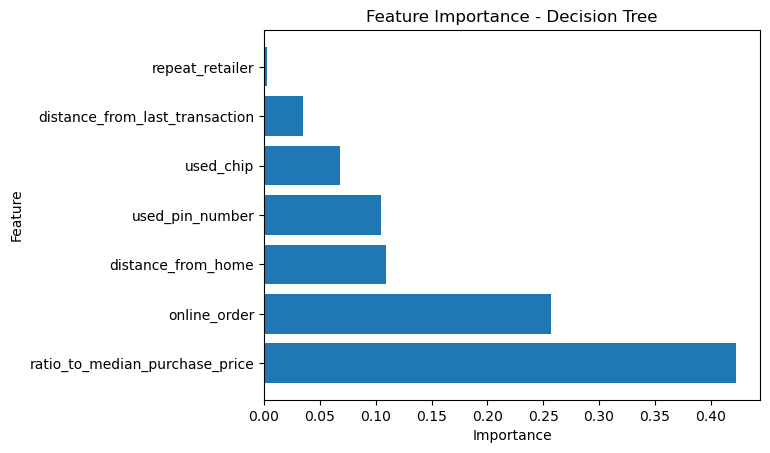
This shows that the ratio_to_median_purchase_price is the most important feature for determining whether a transaction is fraudulent or not. Whether a transaction is online, is important as well.
Let’s also look at the feature importance of the Random Forest model
# Create a DataFrame with the feature importance
df_feature_importance_rf = pd.DataFrame({'Feature': X_train.columns, 'Importance': clf_rf.feature_importances_})
df_feature_importance_rf = df_feature_importance_rf.sort_values('Importance', ascending=False)
# Plot the feature importance
plt.barh(df_feature_importance_rf['Feature'], df_feature_importance_rf['Importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance - Random Forest')
plt.show()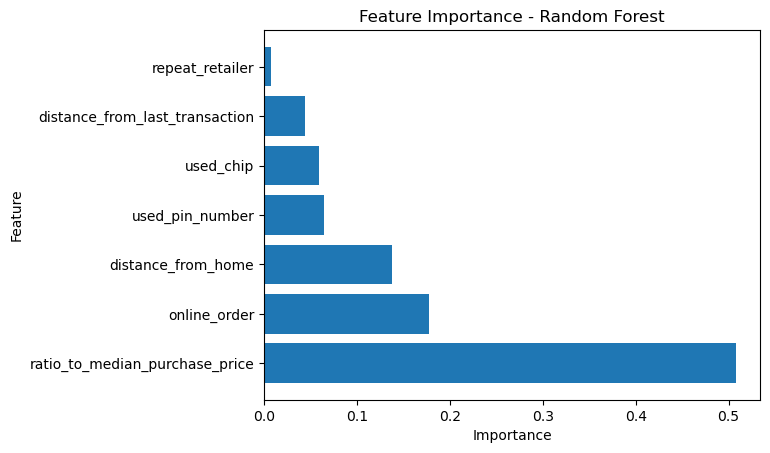
Somewhat surprisingly, XGBoost seems to have picked up on different features than the Decision Tree and Random Forest models. The most important feature is online_order, followed by ratio_to_median_purchase_price as you can see from the plot below
# Create a DataFrame with the feature importance
df_feature_importance_xgb = pd.DataFrame({'Feature': X_train.columns, 'Importance': clf_xgb.feature_importances_})
df_feature_importance_xgb = df_feature_importance_xgb.sort_values('Importance', ascending=False)
# Plot the feature importance
plt.barh(df_feature_importance_xgb['Feature'], df_feature_importance_xgb['Importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance - XGBoost')
plt.show()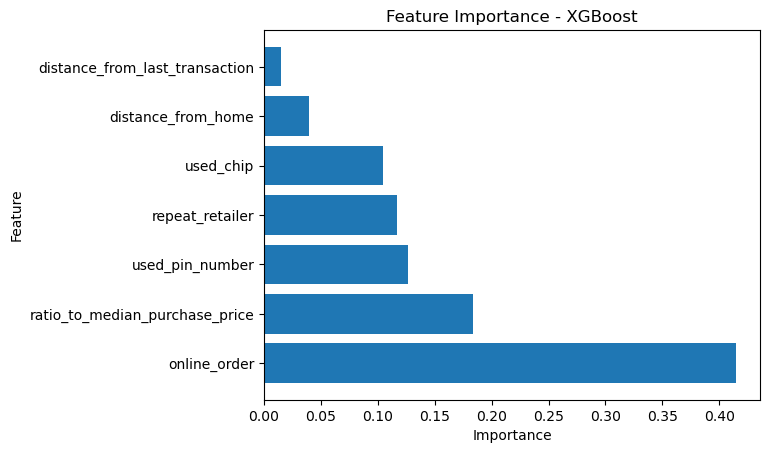
3.6.6 Permuation Importance
We can also look at the permutation importance of each model. The permutation importance is a measure of how much each feature contributes to the model’s predictions. The permutation importance is calculated by permuting the values of each feature and measuring how much the model’s performance decreases. Let’s start with the Decision Tree model
# Calculate the permutation importance
result_dt = permutation_importance(clf_dt, X_test, y_test, n_repeats=10, random_state=0)
# Create a DataFrame with the permutation importance
df_permutation_importance_dt = pd.DataFrame({'Feature': X_train.columns, 'Importance': result_dt.importances_mean})
df_permutation_importance_dt = df_permutation_importance_dt.sort_values('Importance', ascending=False)
# Plot the permutation importance
plt.barh(df_permutation_importance_dt['Feature'], df_permutation_importance_dt['Importance'])
plt.xlabel('Accuracy Decrease')
plt.ylabel('Feature')
plt.title('Permutation Importance - Decision Tree')
plt.show()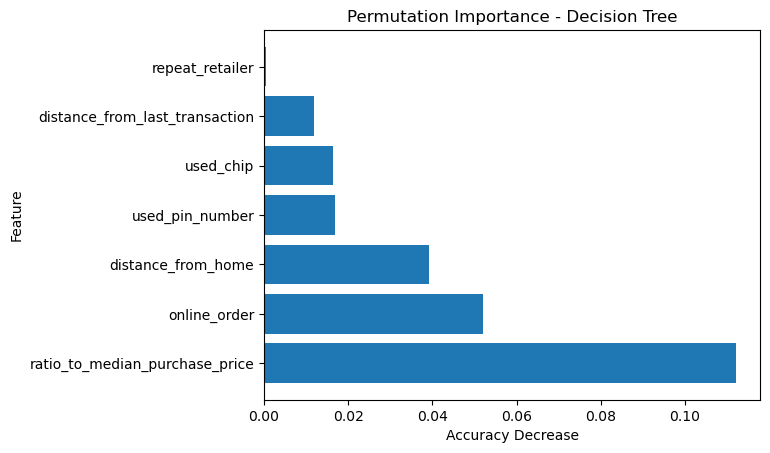
Let’s also look at the permutation importance of the Random Forest model
# Calculate the permutation importance
result_rf = permutation_importance(clf_rf, X_test, y_test, n_repeats=10, random_state=0)
# Create a DataFrame with the permutation importance
df_permutation_importance_rf = pd.DataFrame({'Feature': X_train.columns, 'Importance': result_rf.importances_mean})
df_permutation_importance_rf = df_permutation_importance_rf.sort_values('Importance', ascending=False)
# Plot the permutation importance
plt.barh(df_permutation_importance_rf['Feature'], df_permutation_importance_rf['Importance'])
plt.xlabel('Accuracy Decrease')
plt.ylabel('Feature')
plt.title('Permutation Importance - Random Forest')
plt.show()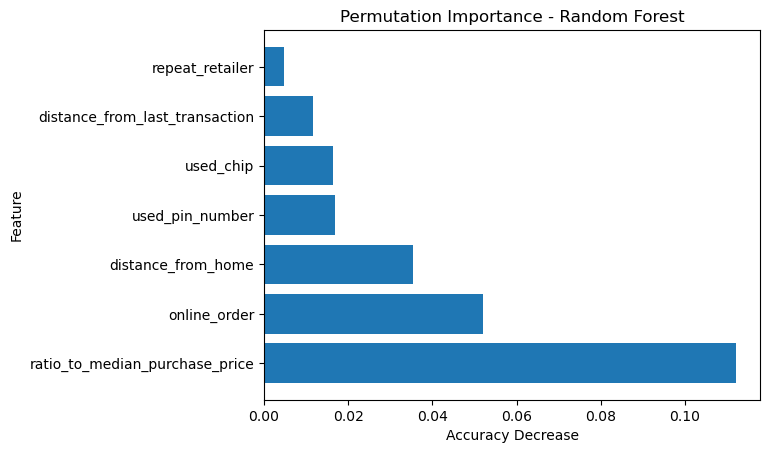
Let’s also look at the permutation importance of the XGBoost model
# Calculate the permutation importance
result_xgb = permutation_importance(clf_xgb, X_test, y_test, n_repeats=10, random_state=0)
# Create a DataFrame with the permutation importance
df_permutation_importance_xgb = pd.DataFrame({'Feature': X_train.columns, 'Importance': result_xgb.importances_mean})
df_permutation_importance_xgb = df_permutation_importance_xgb.sort_values('Importance', ascending=False)
# Plot the permutation importance
plt.barh(df_permutation_importance_xgb['Feature'], df_permutation_importance_xgb['Importance'])
plt.xlabel('Accuracy Decrease')
plt.ylabel('Feature')
plt.title('Permutation Importance - XGBoost')
plt.show()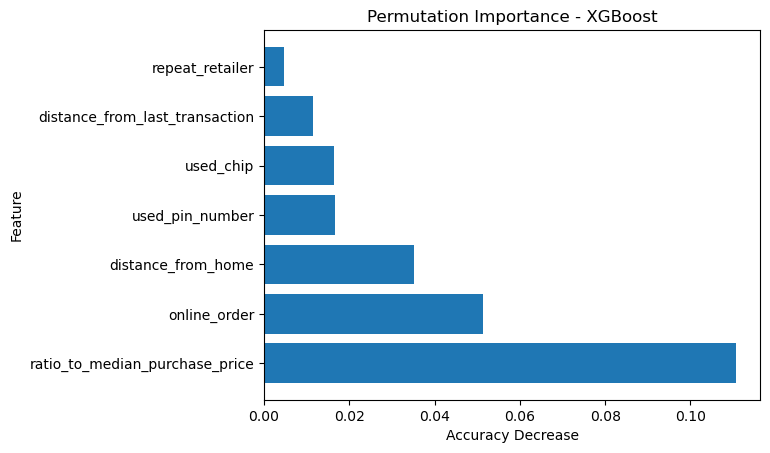
Here the results for the three models are quite similar. The most important feature is ratio_to_median_purchase_price, followed by online_order.
3.6.7 Conclusions
In this notebook, we have seen how to implement decision trees, random forests, and XGBoost classifiers in Python. We have also seen how to evaluate the performance of these models using metrics such as accuracy, precision, recall, and ROC AUC. We have seen that the Random Forest and XGBoost models perform better than the Decision Tree model. Furthermore, we looked at the feature and permutation importance of each model to see which features are most important for determining whether a transaction is fraudulent or not.
Note to handle missing input data one can use “backup” variables that are correlated with the variable of interest and can be used to make a split whenever the data is missing. Such splits are called surrogate splits. In the case of categorical variables, one can also use a separate category for missing values.↩︎